
Agentic vs Deterministic
A decision playbook

Cool doesn’t mean optimal
“Let’s use an agent.”
I hear that a lot. Agents are exciting: they plan, they choose tools, they adapt. But the uncomfortable truth is that most product work doesn’t need autonomy; it needs predictability. If a fixed sequence of steps solves the problem, you don’t get extra points for using a planner. You pay for it—in latency, cost, and debugging time.
This article is a practical guide to that decision. We’ll start by defining what “deterministic” and “agentic” actually mean in practice, then walk through a simple decision rule, discuss baselines that make an agent earn its keep, and close with deployment guidance and a checklist you can actually use.
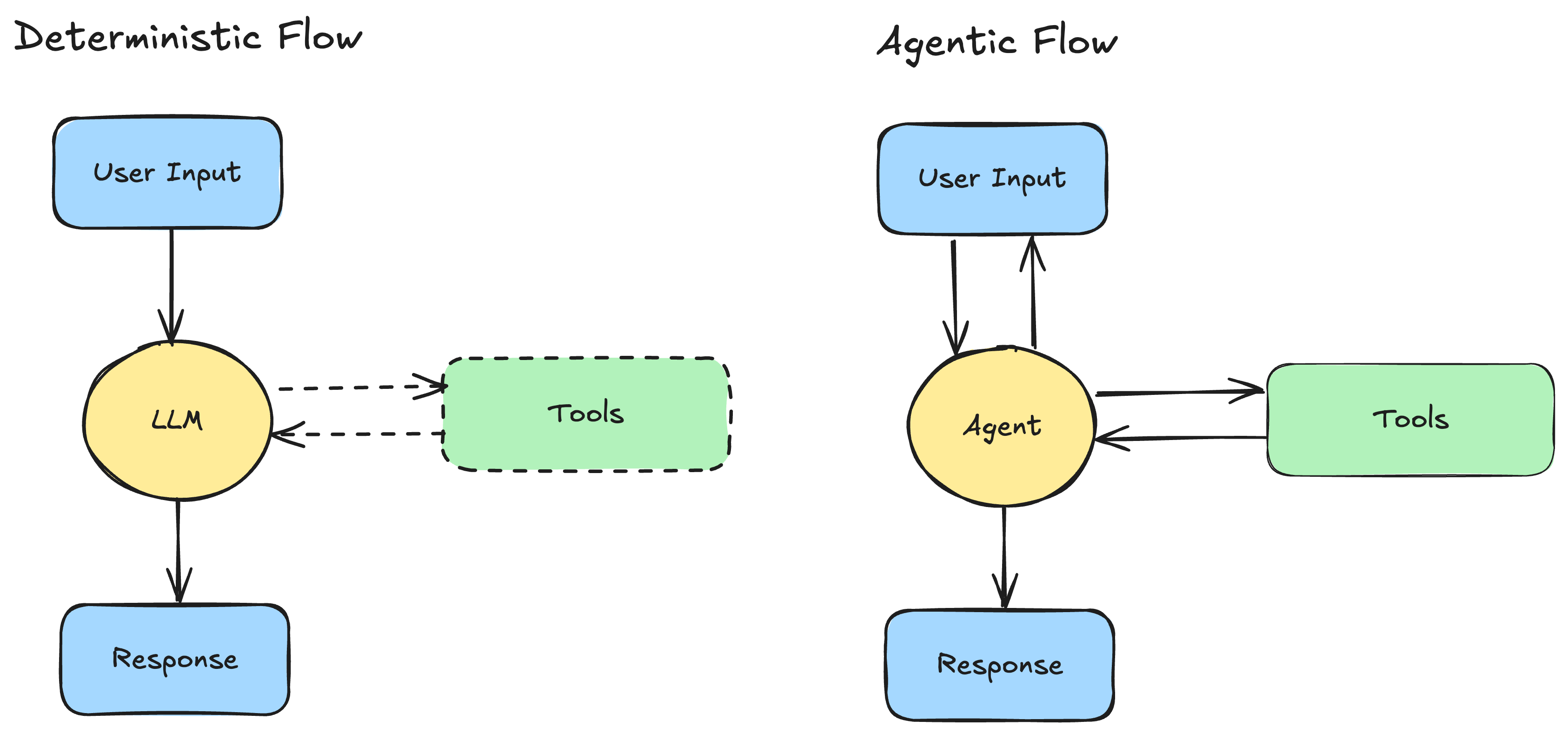
Deterministic vs Agentic
Deterministic LLM flow.
Think of a small directed acyclic graph (DAG) with known steps and a stable tool order. For example: identify intent → retrieve information → rank → compose. You can draw it on a whiteboard and it runs that way every time. It’s traceable, testable, and relatively cheap to operate. The LLM is a component inside a controlled pipeline—usually one call per request, maybe two.
Agentic flow.
Here the model decides at run-time what to do next. It may pick tools, ask for clarifications, loop on sub-goals, or re-plan. That flexibility unlocks use cases you can’t easily script, but it introduces coordination overhead and non-determinism. You’ll need better observability and a plan for failures.
Working Rule: Use determinism wherever control is possible. Add autonomy where the path cannot be anticipated.
Start from outcomes, not architecture
When you want to hang a poster on a wall, you first consider where it goes, how it should look and what it’s made of – then you pick the simplest tool to do the job with the minimum effort and with the least maintenance. You don’t use a hammer and a nail for a paper poster (although I have seen this!) unless it is inside a frame.
However, when building GenAI applications, many times the mindset is “I want to use this big shiny hammer, bring me that poster!”.
What we should actually do though is to flip the script. Pin down outcomes and constraints before choosing our toolbox:
Success metric(s): how will we evaluate the solution?
Latency budget: p95, not the happy path.
Cost budget: tokens, tools, retries (all-in cost per task).
Failure cost: what happens when we’re wrong?
Auditability & compliance: do we need to explain or reproduce decisions?
Write these as acceptance criteria. Then pick the architecture that satisfies them.

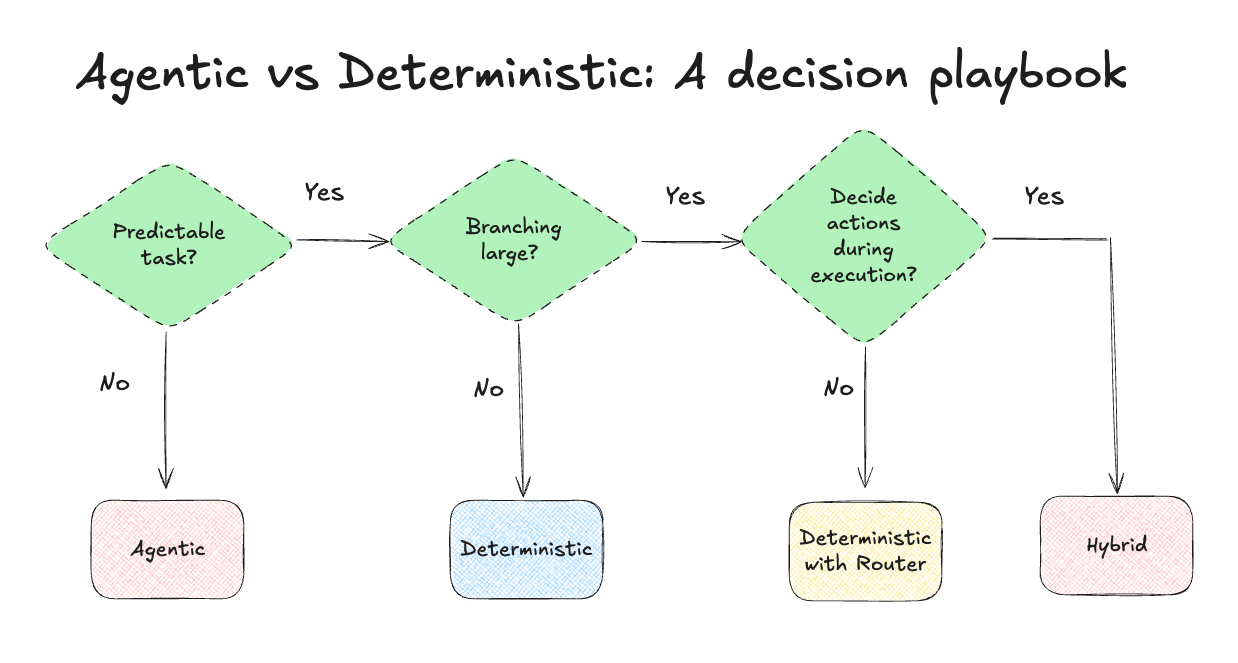
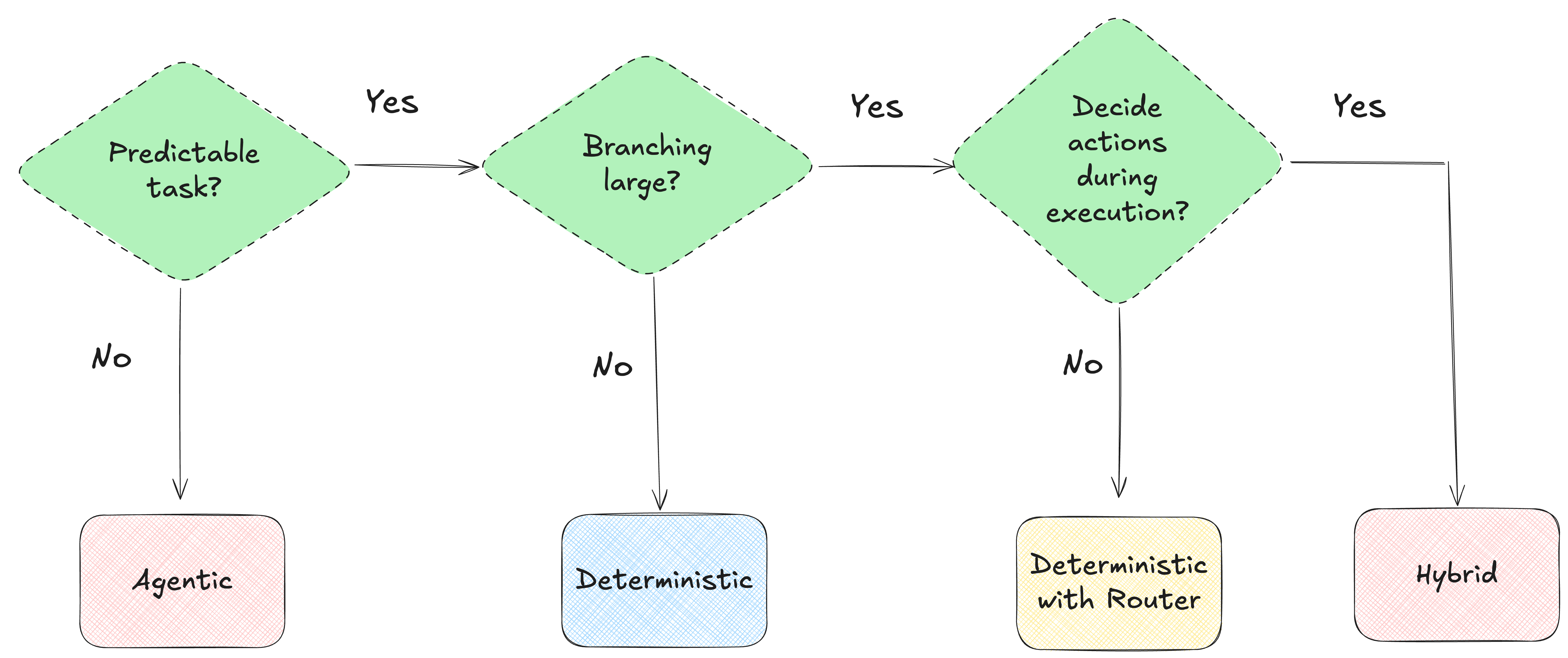
The decision tree
Choosing the right architecture is a complex decision that heavily depends on the use case. I have simplified this decision process and brought it down to 3 critical questions. To decide what architecture to use, ask these in order:
Q1: Task Predictability
Can we write a clear recipe for typical cases (no “it depends”)?
No → This is an indication that an agentic or hybrid workflow is the best candidate for the problem.
Yes → Q2.
Q2: Branching Complexity
Does a straightforward recipe explode into many conditional routes or exceptions?
No → Deterministic flow with a fixed DAG and optional tool call(s).
Yes → Q3.
Q3: Decisions during execution?
Do tool choice/order depend on intermediate results (or do we need clarifying questions mid-flow)?
No → Deterministic with a router. Use a static router which routes to a few sub-DAGs for the major branches.
Yes: → Hybrid / Agentic. Use a router to agentic or deterministic sub-DAG.
The modeling options
Deterministic.
A simple DAG that may include one or more LLM calls, tools, or functions.
Deterministic with router.
A lightweight router (LLM or classifier) sends the request to one of a few sub-graphs. Each sub-graph is a deterministic flow like (1).
Agentic.
An agent (planner/executor) breaks the task into sub-tasks, uses tools, and adapts. Multi-agent setups add specialized roles but also add cost, latency, and operational risk.
Hybrid.
A router chooses between deterministic and agentic flows based on task complexity. You keep it simple for the bulk of traffic and invoke the agent only when complexity is high.
Baselines that make an agent earn its keep
To justify the added complexity, your agent must beat a credible non agentic baseline. Two options are:
Single-LLM monolith: One strong prompt with fixed tool usage (if needed).
Deterministic LLM flow: A repeatable sequence of LLM/tool calls capturing the most common paths (aim for ~80% coverage).
The baseline’s job is to be simple, stable, reproducible—and good enough to make the agent earn its complexity.
Making informed deployment decisions
Before deployment, we should evaluate the agentic setup with the baseline offline, and measure key metrics that can shed light on the tradeoff between performance and cost.
Data. Start by gathering a dataset with production data of both systems. If this is not possible, synthesize one either manually or with the aid of an LLM. If you do the latter, make sure to manually review it because the dataset quality is very important for high quality outcomes.
Measure.
Task Performance: Your success metric (e..g pass@k), judge-LLM or human rubric.
Cost: Total cost per example (tokens, tools retries); track median and p95.
Latency: End-to-end p50 and p95.
Operational burden: Number of prompts and components to maintain, traceability, rollback ease.
To make an informed decision, create a table with the computed metric values for the agentic flow and the baseline. Consider which of these metrics is the most important for your use case, and what is the performance gain X that would justify the added cost, latency and operational complexity.
Decision Rule. Promote the agent only if it beats the baseline by Δ >= X on performance and meets your cost/latency/SLOs. Otherwise, deploy the deterministic flow and keep the agent for R&D or for the hard cases.
Sensitivity Matters: For sensitive use cases (fraud detection), even an 1% gain in task performance might justify a significant increase in cost, while for others an increase in latency might make the whole system ineffective. Whatever the use case is though, having a clear view of the tradeoff between these key metrics for the agent and its baseline, can help you make decisions based on data, and not based on hype!
The real test is an A/B experiment on a business metric with monetary impact. Track supporting engagement metrics, but decide on the business outcome.
Tips & Tricks
Maintainability & Observability. Deterministic systems are boring in the best way: Unit tests pass, traces are linear, audits are simple. Agentic systems are powerful and messy: they need structured logging, step-level traces, correlation IDs, replay, limits (max steps, tool budgets, timeouts), and clear fallbacks. Build those first, not after the first incident.
Compute Return on Investment. Estimate the monetary value of the agent’s Δ performance and subtract the extra cost (tokens, tools, retries), latency impact, and operational burden. If ROI is positive, proceed to A/B.
Guardrails & Fallbacks. Secure against abuse and failure modes. Enforce verifiers, allow-lists for tools, step/time budgets, and always have a deterministic fallback for business continuity (e.g., when the agent hits step/timeout limits).
If you are a startup founder. In case you have a startup and use LLM-based agentic systems as part of your offering, always compare against non agentic baselines and be transparent about trade-offs. Nothing erodes investor trust faster than a fancy solution that underperforms a simpler one.
Closing Thoughts – Deploy the simplest architecture that works
Agents aren’t the goal. A working product is. Start with the smallest deterministic flow that can possibly work. Add autonomy only where the path genuinely can’t be scripted. Measure the gain, price the cost, and make the trade-off explicit. If you do that, you’ll ship faster now—and you’ll still understand your system six months from now.
I publish practical playbooks like this every month. Subscribe to the Beyond the Demo Substack (inbox) and the Beyond the Demo LinkedIn Newsletter (feed).